Recientemente se ha aprobado el estatuto de la Agencia Española de Supervisión de la Inteligencia Artificial (AESIA), marcando así un hito en la regulación de la inteligencia artificial en España y su alineación con las normativas europeas. El pasado 2 de septiembre de 2023 se publicó en el Boletín Oficial del Estado (BOE) el Real Decreto 729_2023 (Disposición 18911 del BOE núm. 210 de 2023), que establecía el marco para supervisar y regular la inteligencia artificial (en adelante, IA) en el país. Así, en un plazo máximo de tres meses, AESIA estará plenamente operativa y convertirá a España en el primer país europeo en contar con un órgano de estas características.
Este acontecimiento es un fiel reflejo de la creciente importancia de la inteligencia artificial, tecnología que está generando un profundo impacto en diversos sectores, incluida la fiscalidad. Y las empresas se están adaptando activamente para incorporar esta tecnología en sus procesos de negocio.
En el ámbito fiscal, los máximos responsables – figuras como los Head of Tax o los Chief Tax Officer – están liderando la implantación de modelos de machine learning (en adelante, ML) en procedimientos como pueden ser la realización de reportes internos o la adaptación a los requerimientos constantes de las administraciones públicas. Todo ello forma parte de una estrategia más amplia para aprovechar de manera efectiva los datos que sus sistemas informáticos procesan cada año (ERPs, CRMs etc), con el objetivo de convertir sus organizaciones en entidades impulsadas por datos, es decir, data-driven, donde cada decisión se basa en información sólida y respaldada por datos.
Una de las tecnologías más importantes y que ha facilitado que hoy podamos hablar de IA es el machine learning. Pero ¿qué cabida tiene realmente el en la función fiscal? ¿Qué puede hacer un fiscalista para integrar el ML en los procesos objeto de su responsabilidad? Para responder a esa pregunta conviene recordar que la inteligencia artificial integra, entre otros, varios conceptos como el propio machine learning, el aprendizaje profundo (eep learning), o las redes neuronales (neural networks).
Mientras que la inteligencia artificial es la capacidad de un sistema informático para imitar las funciones cognitivas humanas, como el aprendizaje y la resolución de problemas, edentro del ML, encontramos tipos de modelos de aprendizaje que tienen aplicación en el desarrollo de la función fiscal: el supervisado, el no supervisado y el aprendizaje por esfuerzo.
Estos modelos utilizan sets de datos etiquetados con una categorización realizada previamente por seres humanos, lo que permite Con cada nueva ingesta de datos, el modelo puede aprender y ganar precisión con el paso del tiempo.
Esta tipología de aprendizaje puede ser utilizada en procesos de inspecciones fiscales. La información disponible derivada del histórico de litigios fiscales – entre otros, comunicaciones de inicio, diligencias, o actas de inspección – facilitan un colectivo de datos que puede ayudarnos a predecir resultados de inspección y hacer una prescripción de acciones a llevar a cabo dependiendo de variables como el equipo inspector o el alcance de la inspección. Se utilizan para tal fin algoritmos como los árboles de decisión, Naive Bayes, o la regresión logística.
Asimismo, existen modelos de previsión o forecasting a través de los cuales, utilizando datos propios de la operativa fiscal – en grandes corporaciones, los datos Country by Country reportados en el modelo 231 de la AEAT de años anteriores y las variables que los determinan – podremos hacer una previsión de las cifras a reportar en este modelo para años próximos.
Por otro lado, los modelos de aprendizaje no supervisado se utilizan cuando los sets de datos no están previamente etiquetados o categorizados. Generalmente, . Uno de los modelos más comunes es el de clustering, entendiendo por clústers las agrupaciones que nos permiten hacer una categorización de los datos.
Un caso de uso en el ámbito fiscal sería la identificación de cambios normativos que pudieran tener impacto en nuestra empresa. Partiendo de una base de datos que integre los cambios normativos a nivel global, se pueden utilizar modelos de aprendizaje automático de clustering que nos ayuden a identificar tendencias normativas, categorizar las novedades fiscales globales o evaluar el posible impacto que puedan tener en nuestra corporación.
Otro claro ejemplo de aprendizaje no supervisado sería el de detección de anomalías. Partiendo de una serie de datos históricos – podríamos utilizar de nuevo los datos del Country by Country del modelo mencionado anteriormente – podemos detectar anomalías que nos ayuden a anticipar posibles inconsistencias, y así prevenir potenciales sanciones que nos pudiera imponer la administración. En definitiva, estaríamos aplicando el machine learning como una herramienta preventiva.
Este último aprendizaje funciona por el método de prueba y error, de modo y manera que el sistema elegirá la mejor opción en base a un sistema de recompensas a través del cual el resultado de las acciones realimenta el set de datos. El ejemplo más representativo es la predicción del texto que vamos a escribir en los cuadros de búsqueda de páginas web. Llevándolo al ámbito fiscal, podríamos pensar en un complejo sistema que ayude a fiscalistas a defender sus casos en los tribunales generando argumentos y contraargumentos persuasivos basados en las evidencias y las normas legales y, por ende, facilitar la toma de decisiones.
En definitiva, se pone de manifiesto que el aprendizaje automático dispone de diferentes tipologías, y todas ellas son explotables por los responsables fiscales. La cuestión es: sin ser un experto en ciencia de datos, ¿cómo sabe un fiscalista qué sistema de aprendizaje automático debe utilizar? A través del siguiente flujograma publicado por Thomas Malone de la Universidad MIT Sloan se puede identificar el tipo de sistema de ML que debe utilizarse en función de determinadas variables y los objetivos del proceso:
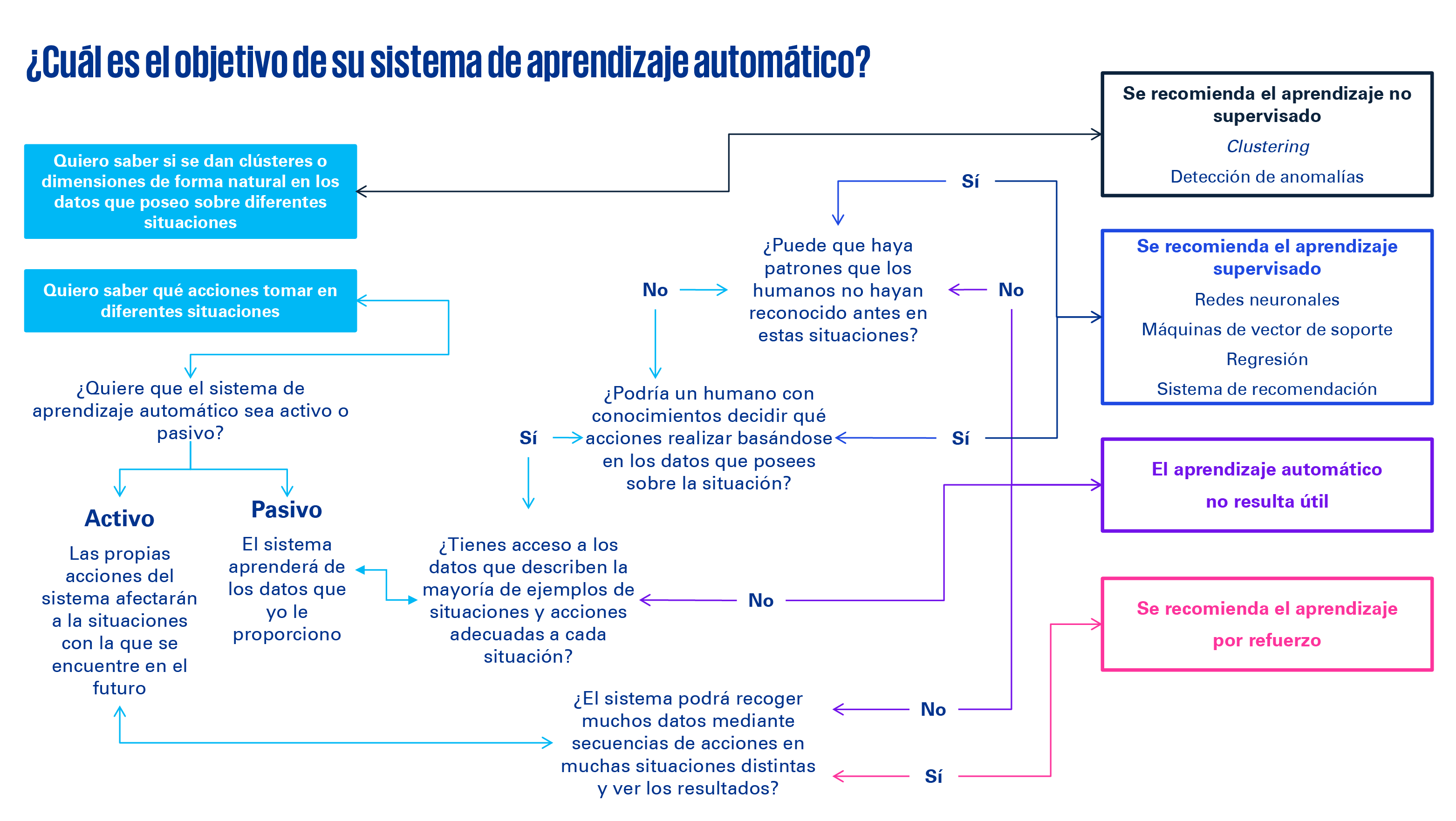
Planteando las preguntas adecuadas, concluimos que el aprendizaje automático es, por tanto, una herramienta que nos ayuda a aumentar la eficiencia en los procesos fiscales, reducir errores y minimizar el riesgo de sanciones. No obstante, además de los beneficios que nos ofrece el aprendizaje automático en la fiscalidad y de la aparente simplicidad en el proceso de detección del modelo a utilizar, hay otras consideraciones clave para su correcta implantación. Alineados con la normativa sobre Inteligencia Artificial aprobada por el Parlamento Europeo en junio 2023, algunos de estos aspectos son:
En un futuro no tan lejano, anticipamos una mayor automatización de tareas fiscales rutinarias, la interacción en tiempo real con las autoridades tributarias, y la expansión de la inteligencia artificial. Es por ello que las organizaciones deben alinear sus estrategias fiscales con un enfoque en la gestión de datos y un énfasis especial en la ética, la privacidad y la supervisión humana en el uso de la tecnología fiscal.